Reasoning with Training KV Cache (ReasonCACHE). ReasonCACHE adapts a frozen backbone
by learning a trainable KV cache (prefixes) at each attention layer, compressing demonstrations
into a compact cached state. In contrast, (a) in-weight methods adapt by updating model
parameters, and (b) in-context learning adapts only through additional exemplar
tokens at inference time. (Right) Test accuracy (%) on GPQA-Diamond where ReasonCACHE outperforms both in-context
and in-weight baselines, and surpasses full supervised fine-tuning.
Abstract
Can Large language models (LLMs) learn to reason without any weight update
and only through in-context learning (ICL)? Acquiring complex reasoning capabilities
typically requires learning from many demonstrations. However, standard ICL approaches
break down at this scale: attention costs grow quadratically, performance degrades, and
learning becomes shallow as the context is overloaded. Due to these limitations,
practitioners predominantly rely on in-weight learning (IWL) to induce reasoning. We
show that by using Prefix Tuning, LLMs can learn to reason without overloading
the context window and without any weight updates. We introduce ReasonCACHE,
an instantiation of this mechanism that distills demonstrations into a fixed key-value
cache. Empirically, across challenging reasoning benchmarks, including GPQA-Diamond,
ReasonCACHE outperforms standard ICL and matches or surpasses IWL approaches.
Further, it achieves this all while being more efficient across three key axes: data-,
inference-, and parameter-efficiency. Theoretically, we prove that ReasonCACHE can be
strictly more expressive than low-rank weight update since the latter ties expressivity
to input rank, whereas ReasonCACHE bypasses this constraint by directly injecting
key-values into the attention mechanism.
The Mechanism Behind Prefix Tuning
As shown in the figure above, Prefix tuning (PT) adds m trainable key–value vectors at each transformer layer $l$ i.e.
$(P_K^{(ℓ)}, P_V^{(ℓ)}) \in \mathbb{R}^{m \times d}$. These prefix keys and values are prepended
to the token-derived keys and values $(K^{(\ell)}, V^{(\ell)})$ respectively, so each attention layer operates over both prefix and token information.
$$ \tilde{K}^{(\ell)} =
\begin{bmatrix}
P_K^{(\ell)} \\[2pt]
K^{(\ell)}
\end{bmatrix},
\qquad
\tilde{V}^{(\ell)} =
\begin{bmatrix}
P_V^{(\ell)} \\[2pt]
V^{(\ell)}
\end{bmatrix} $$
All pretrained weights are frozen; only $\mathcal P=\{(P_K^{(\ell)},P_V^{(\ell)})\}_{\ell=1}^L$ is optimized
to minimize the standard next-token prediction loss. We use ReasonCACHE to denote Prefix Tuning specialized to reasoning.
Note that ReasonCACHE introduces no new adaptation primitive; rather, it studies and demonstrates how learned KV prefixes can scale in-context learning
into a reliable and efficient mechanism for reasoning.
Experimental Results
1. Effective Reasoning Without Weight Updates
(a) ReasonCACHE Scales In-Context Learning. We first observe a clear limitation of
shallow contextual adaptation: both ICL and prompt tuning yield only modest gains, especially on long-horizon reasoning.
In contrast, ReasonCACHE consistently outperforms other in-context methods.
(b) ReasonCACHE Outperforms In-Weight Adaptation. We next compare ReasonCACHE to IWL methods.
Even under matched parameter budgets, and with pretrained weights frozen, ReasonCACHE matches or
beats LoRA and even full SFT, with the gap widening on long-form reasoning. Specifically, ReasonCACHE
achieves the best performance on GPQA-Diamond ($41.92\%$), exceeding both LoRA and full SFT.
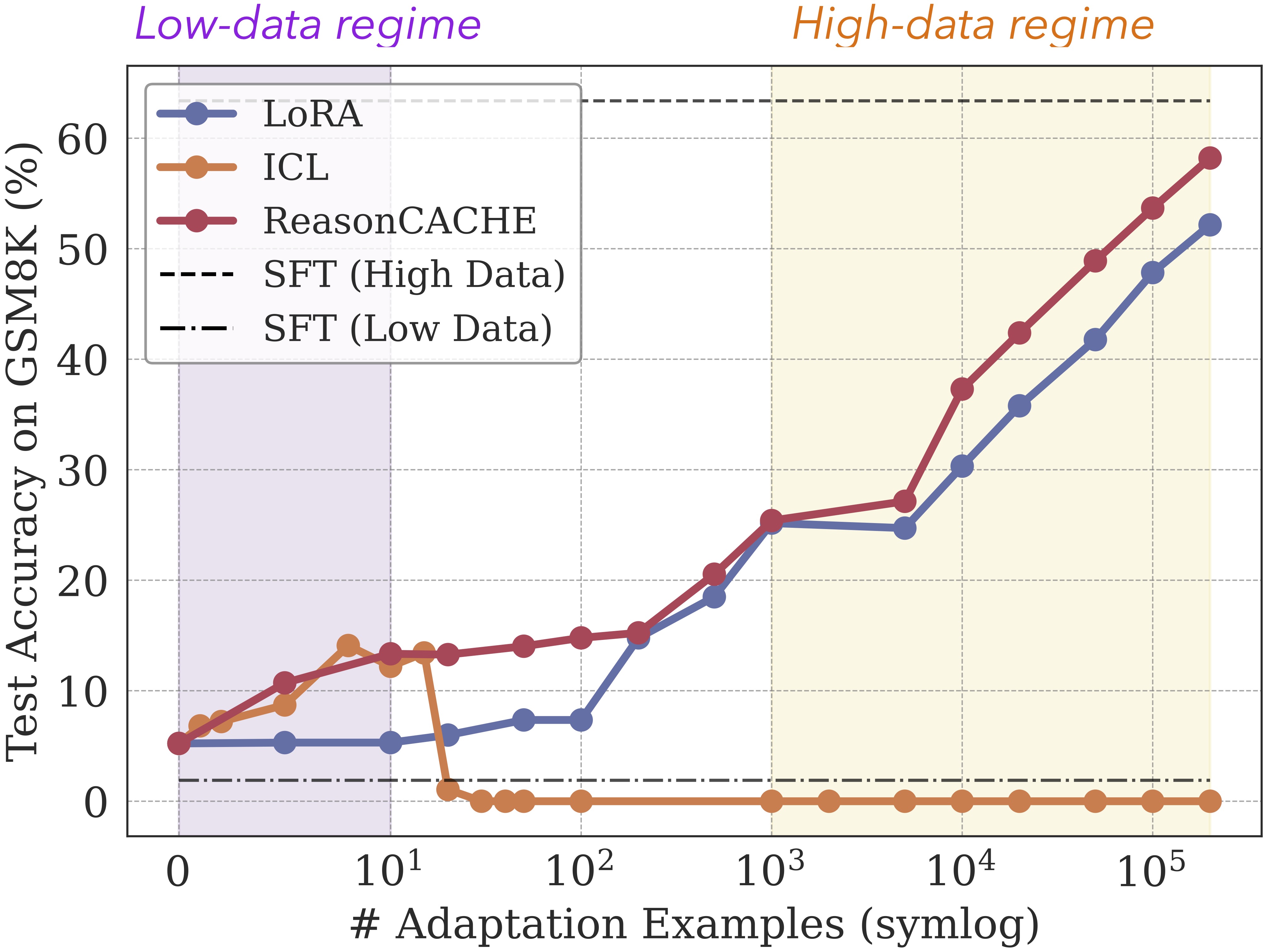
2. ReasonCACHE is Data Efficient
ReasonCACHE traces the accuracy–data Pareto frontier over nearly four orders of magnitude. In the
low-data regime, ReasonCACHE matches or exceeds ICL, while ICL degrades as examples accumulate
due to long-context dilution and position effects. IWL methods (e.g., LoRA, SFT)
often overfit with limited data. ReasonCACHE is $\approx59$% more data-efficient than LoRA
(to reach 50% accuracy), outperforms it throughout this regime, and closes much of the gap to high-data
SFT—all while keeping the backbone frozen. Overall, ReasonCACHE bridges
in-context and in-weight adaptation: it inherits ICL’s inductive bias via few-shot initialization
and gains IWL-style scaling via optimization.
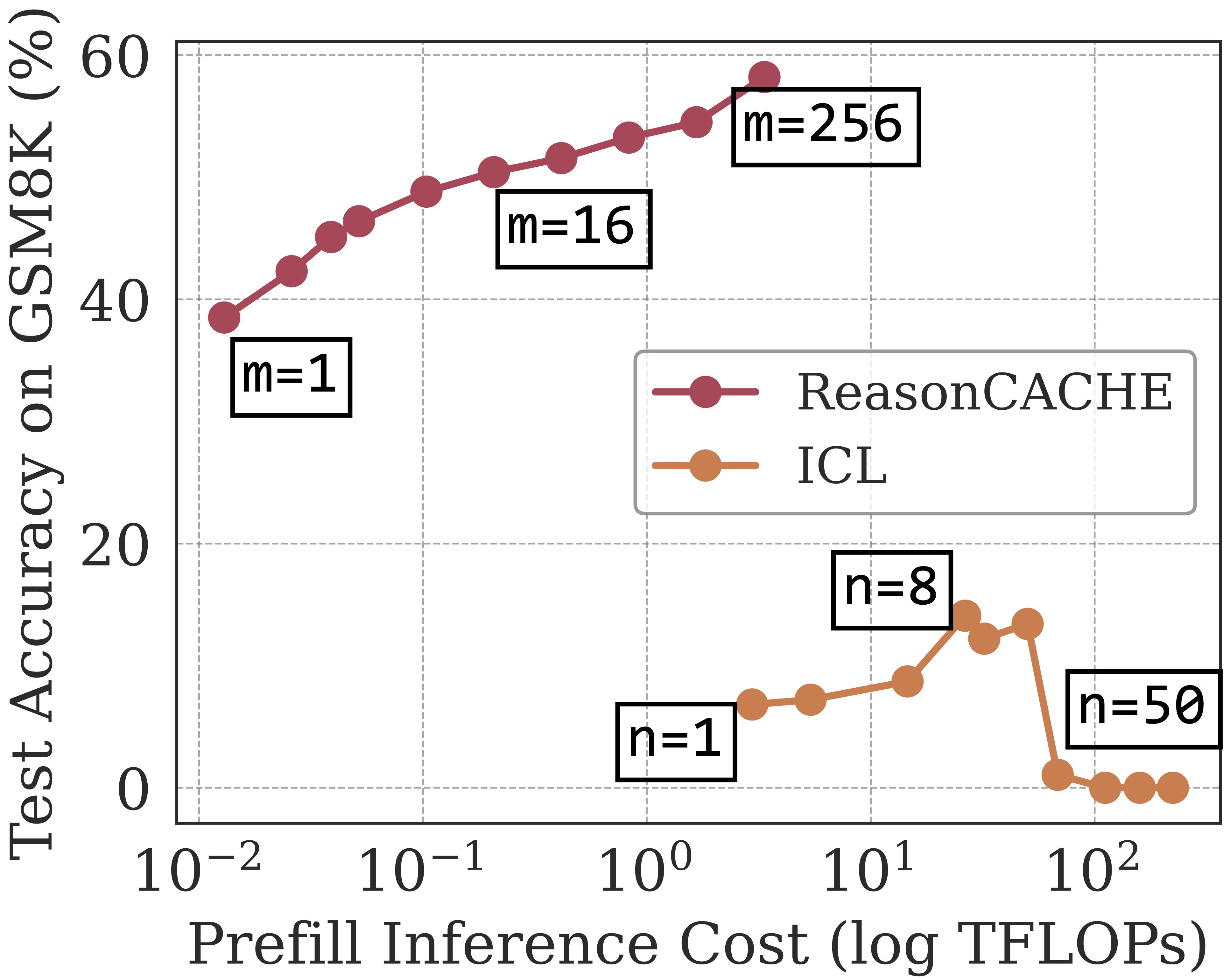
2. ReasonCACHE is Inference Efficient
(a) ReasonCACHE Reduces Prefill Cost. As shown in the figure below (left), ReasonCACHE dominates ICL, outperforming the best ICL configuration by 44.8 points while using
90% less total inference compute. This gap is driven by prefill costs, since ICL incurs
quadratic overhead as demonstrations are added, whereas ReasonCACHE replaces them with a short
learned prefix.
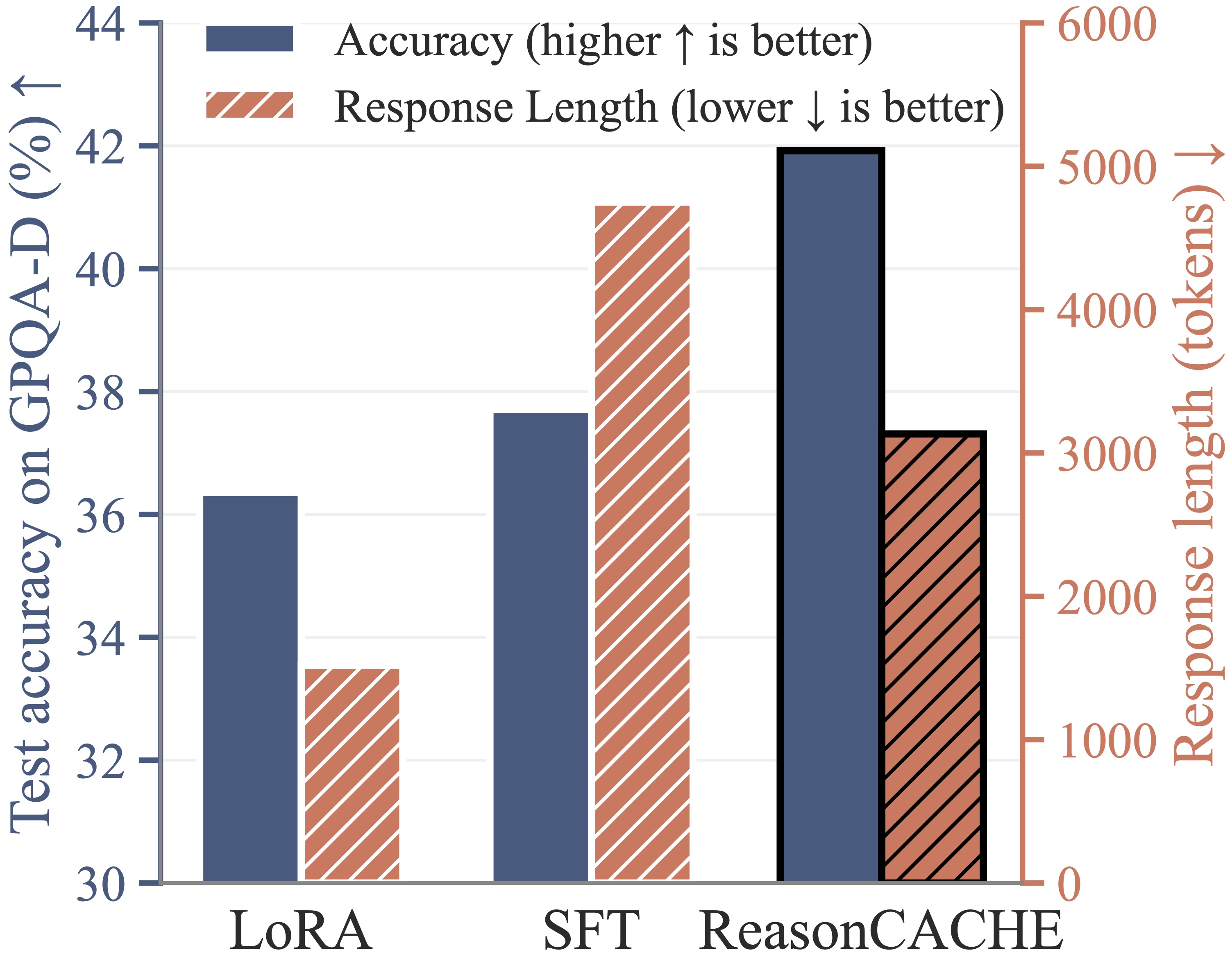
(b) ReasonCACHE Reduces Generation Length. As shown in the figure below (right), on long-form reasoning tasks such as GPQA-D,
decoding dominates inference. ReasonCACHE achieves higher accuracy with substantially shorter
generations (compared to SFT): it reduces generation length by 34% while improving accuracy by 11%.
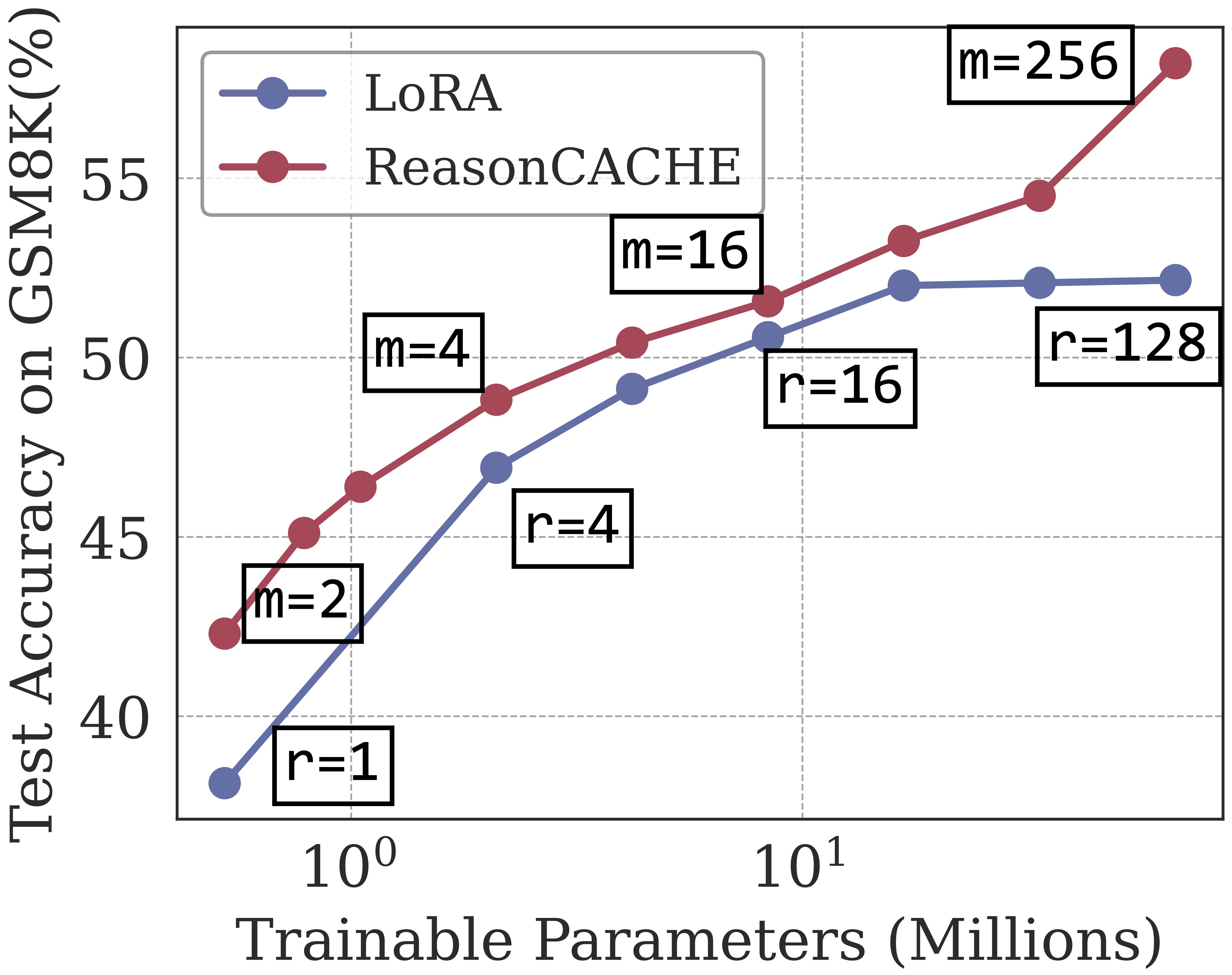
2. ReasonCACHE is Parameter Efficient
Under matched parameter budgets, ReasonCACHE consistently dominates LoRA across
the entire accuracy–parameter curve on GSM8K. For example, to reach a target test accuracy of
50%, it requires 46% fewer parameters than LoRA. ReasonCACHE is more parameter-efficient in the low-budget regime and continues to improve as the budget increases, while LoRA saturates early.
Theoretical Insights
We prove that Prefix Tuning (and thus ReasonCACHE) and LoRA face fundamentally different
expressivity bottlenecks. Both can introduce arbitrary new directions outside the
base model's subspace; the difference is how many independent directions they can realize.
LoRA is jointly constrained by (i) the intrinsic rank of the input context and (ii) the adapter rank.
Prefix Tuning is constrained only by the number of prefix vectors.
Thus, when the input lies in a low-dimensional subspace,
Prefix Tuning can be strictly more expressive than LoRA. For details, please refer to our paper.
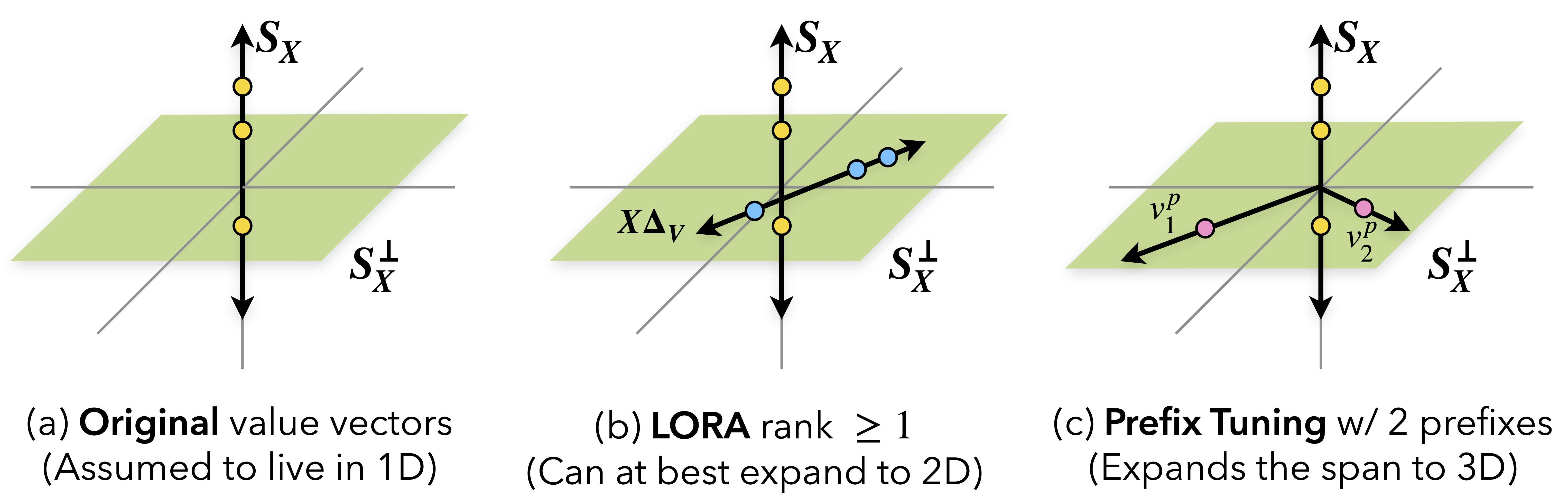
In figure below, input is assumed to be of rank $1$. The original value vectors span a 1D subspace $S_X$ (vertical axis);
any new information must lie in the orthogonal space $S_X^\perp$ (horizontal plane). Here, (a) The base model is confined to $S_X$.
(b) Since LoRA is limited by the rank of input, it adds at most one new dimension regardless of the adapter
rank $r$. (c) Prefix tuning even with two prefixes can span the full 2D space $S_X^\perp$,
which LoRA cannot reach.
To cite this work, please use the following bibtex:
@inproceedings{sharut2026reasoncache,
title={ReasonCACHE: Teaching LLMs To Reason Without Weight Updates},
author={Gupta, Sharut and Isola, Phillip and Jegelka, Stefanie and
Lopez-Paz, David and Ahuja, Kartik and Ibrahim, Mark and Pezeshki, Mohammad},
journal={arXiv preprint arXiv:2602.02366},
year={2026}
}